

Blog

Online datasprint CEMROL: successful public meeting and a look behind the scenes
With a contribution by Lars Punt.
On 3 July 2020, an online datasprint for existing CEMROL volunteers and other interested people took place. In this blogpost, I will seize the opportunity to look back at what our audience is doing for – and with – CEMROL.
First of all, the datasprint: After the two previous activities for volunteers, the SKILLNET team decided to organise another public meeting in the Spring of 2020. Due to COVID-19, it was not possible to meet in person, but fortunately an online ZOOM meeting offered a solution.
The online meeting, with about 14 participants, started with an introduction by the SKILLNET project leader Dirk van Miert. After that, postdoc researcher Ingeborg van Vugt showed the results and visualizations that have been achieved so far. Maybe you have already seen some of them on the SKILLNET website. In CEMROL, a simple overview has been added of the percentage of letters of each language that have already been processed.
Welcome to our volunteers
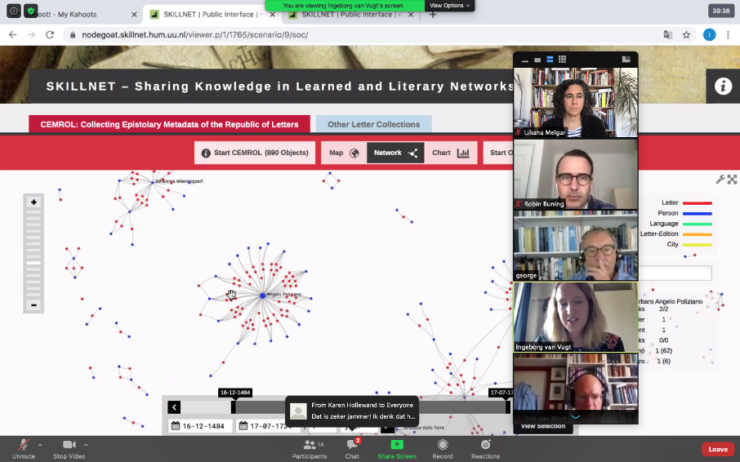
Ingeborg presents some of the results so far
After Ingeborg’s presentation we worked in CEMROL together. In about 45 minutes we collected a lot of new data. There was also room to ask questions. By sharing the screen we were able to watch each others’ moves and make progress. Many of the questions that came up were included on the Frequently Asked Questions page.
Datasprint in progress
After the work was done, it was time for some relaxation. We concluded the meeting with a quiz, using the program Kahoot!, about all kinds of facts about the Republic of Letters and related subjects, such as “How were letters delivered in the early modern era?” and “From what year dates the first known mentioning of the term ‘Republic of Letters’?”.
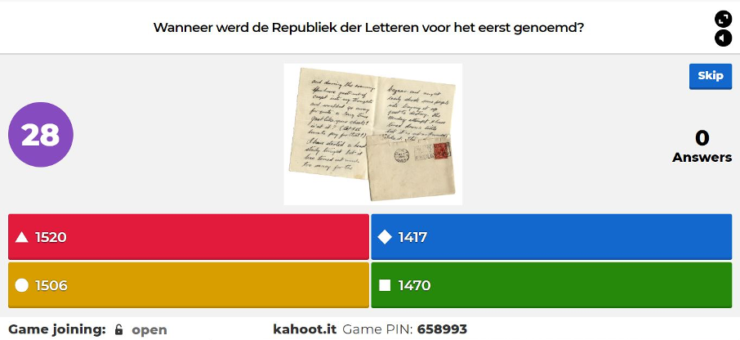
Screenshot of the Kahoot! quiz
The participant who gave the right answer the quickest got the highest number of points. At the end of the quiz the winner was announced and the prize was later sent to his home, which was the book De Republiek der Letteren. De Europese intellectuele wereld 1500-1760 (The Republic of Letters: The European intellectual world 1500-1760) by Hans Bots.
In addition to the volunteer meeting, a lot of work is being done behind the scenes to process all the data. Lars Punt, my fellow intern in the SKILLNET project, explains below what he has done for the project:
When the volunteers have finished marking and transcribing a complete letter edition in CEMROL, a file is automatically created of the generated data, including the marked senders, recipients, dates, places, etc. This list is then ‘cleaned’: all information is checked and, if necessary, corrected and supplemented. When the data for all letters in the letter edition are confirmed, the senders and recipients are provided with multiple identification numbers. For this we use VIAF and EMLO ID’s. These are two databases in which more information about the person can be found, which is also useful because letters are often signed with variations of someone’s name. By using a universal identification number, it can ultimately be established that the letters from different editions are connected to one and the same sender or recipient.
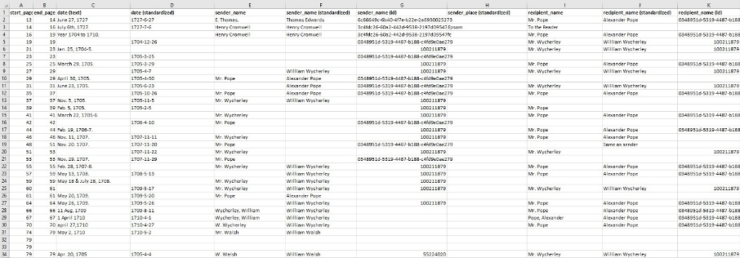
Example of data that still need to be cleaned
Once the entire list is complete, the edition can be added to Nodegoat. This is the data program used by the SKILLNET project. First the specific letter edition has to be added, then all senders and recipients, and finally all individual letters are imported and linked to the right person. Once this has been done, it is possible for the researchers to carry out various visualisations which they can use for their research and which also immediately give a better picture of the resulting network.
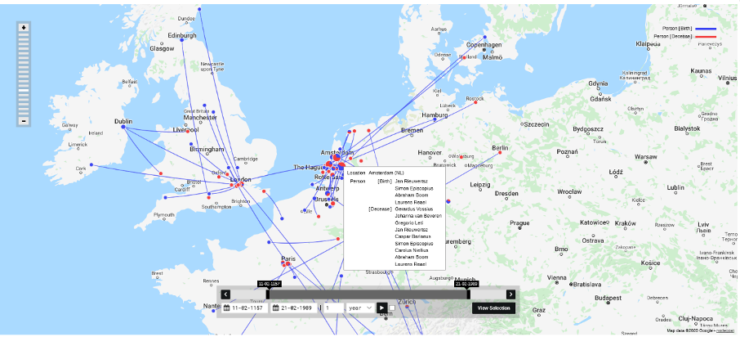
Geographic map of letter senders and recipients
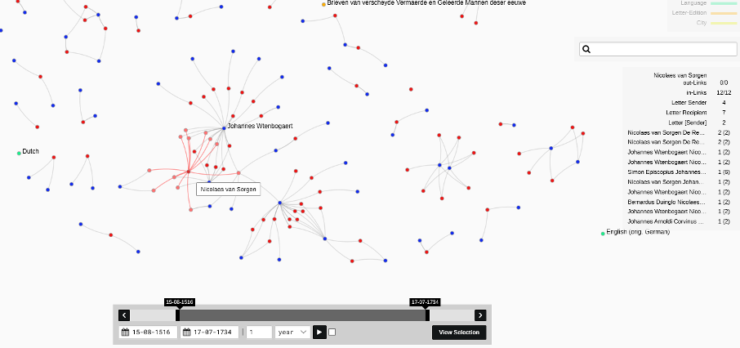
Example of a network visualisation
You must be logged in to post a comment.